
El web crawling es una de las tecnologías más importantes que hacen posible que los buscadores como Google funcionen. Gracias a este proceso, se pueden descubrir y organizar millones de páginas web para que luego aparezcan en los resultados cuando buscamos algo. Aunque suene complicado, entender qué es el web crawling y cómo se usa puede ser más fácil de lo que parece.
En este post vamos a ver con ejemplos sencillos cómo funcionan los robots que recorren internet, qué papel tiene el scraping en todo esto y por qué estas herramientas se usan cada vez más en sectores como el marketing, el análisis de datos o el desarrollo web. Si alguna vez te has preguntado cómo se recopila la información de las páginas o cómo Google sabe lo que hay en cada sitio, aquí tienes la respuesta.

Qué es el web crawling
El web crawling es el proceso mediante el cual un programa informático, llamado crawler o araña web, recorre internet de forma automática para descubrir páginas nuevas o actualizadas. Estos programas siguen los enlaces de una página a otra, como si fueran exploradores que no paran de moverse buscando contenido.
Este rastreo comienza con una lista de páginas web conocidas. A partir de ahí, el crawler visita una página, analiza su contenido y guarda todos los enlaces que encuentra. Luego pasa a visitar esas páginas nuevas y repite el proceso. Así se va construyendo un mapa enorme de la web.
El web crawling es esencial para que los motores de búsqueda como Google puedan indexar las páginas. Es decir, gracias a este proceso, los buscadores pueden saber qué hay en cada sitio web y decidir si lo muestran en los resultados cuando alguien hace una búsqueda.
Además, no todos los sitios se rastrean igual. Algunos crawlers dan prioridad a páginas que se actualizan con frecuencia o que tienen muchos enlaces que apuntan a ellas. También se revisan las páginas ya conocidas cada cierto tiempo para ver si han cambiado.
Proceso de Web Crawling y Web Scraping
1. Exploración
El crawler visita páginas web y sigue enlaces
2. Indexación
Se registran las URLs y el contenido de las páginas
3. Extracción
El scraper obtiene datos específicos de las páginas
¿Qué está pasando?
Pulsa en «Iniciar Crawling» para ver cómo un crawler recorre las páginas web, descubriendo su contenido y enlaces. Luego puedes usar «Iniciar Scraping» para ver cómo se extraen datos específicos de esas páginas.
¿Y el web scraping?
Aunque muchas veces se confunden, el web scraping no es lo mismo que el web crawling.
Mientras que el crawler se dedica a recorrer páginas y descubrir enlaces, el scraper se encarga de extraer información concreta de una o varias páginas web.
Por ejemplo, si quieres obtener los precios de todos los móviles de una tienda online, el scraping es lo que te permite hacerlo de forma automática.
Para lograrlo, el scraper analiza el código HTML de las páginas y busca dentro de él los elementos que contienen los datos que interesan. Esto puede incluir textos, tablas, imágenes o enlaces.
El web crawling descubre las páginas, y el web scraping extrae la información útil de ellas.
El web crawling es como enviar miles de robots a explorar cada rincón de internet, mientras el web scraping les dice exactamente qué información buscar y guardar.
Cómo funciona el web crawling
Para entender bien cómo funciona el web crawling, imagina que tienes un robot muy curioso. Este robot quiere descubrir todo lo que hay en internet. Pero no lo hace al azar. Sigue un proceso muy ordenado y repetitivo.
Te lo explico paso a paso:
- Primero, el robot empieza con una lista inicial de páginas. Esta lista puede tener, por ejemplo, las páginas más conocidas como portadas de periódicos o tiendas online. A esto se le llama conjunto de semillas.
- Después, el robot visita una de esas páginas. Lee su contenido y busca todos los enlaces que hay dentro. Los enlaces son las puertas que llevan a otras páginas.
- Guarda todos esos nuevos enlaces en una lista. Es como si fuera apuntando direcciones que aún no ha visitado.
- Luego, elige una nueva página de esa lista y repite el proceso: entra, lee el contenido, busca enlaces, los guarda… Así hasta recorrer muchas páginas. Esto se llama hacerlo de forma recursiva, porque siempre hace lo mismo una y otra vez.
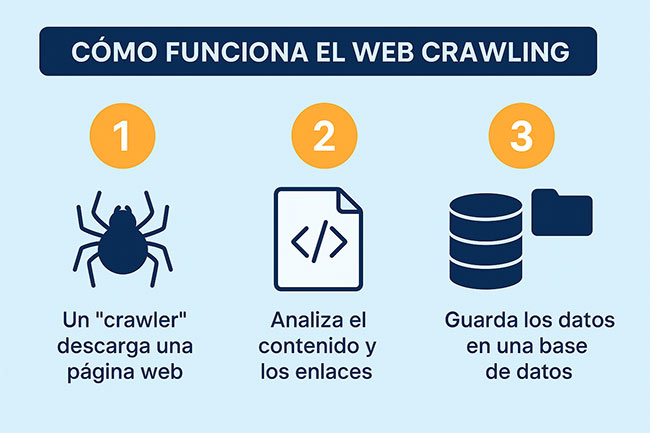
Este sistema le permite al robot explorar gran parte de internet, como si estuviera tejiendo una telaraña gigante de conexiones entre páginas.
Pero no lo hace sin pensar. Los crawlers deciden qué páginas visitar primero. Por ejemplo, pueden dar más importancia a las páginas que tienen muchos enlaces desde otros sitios o que se actualizan con frecuencia.
También vuelven de vez en cuando a páginas que ya han visitado para ver si hay cambios o contenido nuevo. Así, los motores de búsqueda siempre tienen información actualizada.
Gracias a este proceso, los buscadores como Google pueden crear un índice de la web, algo parecido a un catálogo. Sin los crawlers, los buscadores no sabrían qué páginas existen ni qué contienen.
Cómo afecta el web crawling al SEO
El SEO depende en gran parte de que los crawlers puedan acceder y entender bien tu sitio web. Si tu web no está bien estructurada o tiene errores que dificultan el rastreo, es posible que Google no la indexe correctamente.
Uno de los conceptos clave es el crawl budget o presupuesto de rastreo. Google asigna un tiempo y una cantidad de páginas a rastrear por cada sitio web. Por eso, es importante optimizar la estructura para que las páginas más importantes sean las que se rastreen con prioridad.
Aquí van algunas recomendaciones para mejorar el rastreo de tu web:
- Organiza bien los enlaces internos para que el crawler pueda moverse fácilmente por el sitio.
- Evita contenido duplicado, que confunde a los buscadores.
- Asegúrate de que las páginas más valiosas estén accesibles desde el menú o desde otras páginas.
- Mejora la velocidad de carga, ya que un sitio lento puede ser rastreado con menos frecuencia.
- Usa el archivo robots.txt correctamente, indicando qué partes del sitio se pueden rastrear y cuáles no.
Las herramientas de scraping buscan patrones o elementos específicos dentro de ese código, como pueden ser tablas de datos (<table>), párrafos de texto (<p>), títulos (<h1>, <h2>), imágenes (<img>), precios, o enlaces (<a>).
Así que cuida el código y la estructura de tu web. SI usas algún CMS tipo WordPress o PrestaShop, lo tendrás bastante hecho, ya que es un aspecto que estos gestores de contenido cuidan mucho, pero si es una programación a medida, ten cuidado.
Ejemplos y aplicaciones reales del web crawling y el web scraping
Puede que todo esto del web crawling y el web scraping te parezca algo lejano, pero en realidad, muchas de las cosas que ves en internet cada día funcionan gracias a estas tecnologías. Aquí tienes algunos ejemplos reales que te ayudarán a entenderlo mejor.
1. Motores de búsqueda como Google
Este es el ejemplo más conocido. Google usa crawlers para recorrer toda la web, descubrir nuevas páginas y actualizar la información que ya tiene. Así, cuando haces una búsqueda, te puede mostrar los resultados más relevantes y actuales. Sin el web crawling, los buscadores no podrían funcionar.
2. Comparadores de precios
¿Alguna vez has usado un comparador de precios para saber dónde está más barato un producto? Estas webs usan scraping para revisar varias tiendas online y sacar los precios, las características del producto y si está disponible o no. Todo eso se actualiza en tiempo real gracias a este sistema.
3. Seguimiento de ofertas de empleo
Hay páginas que recogen ofertas de trabajo de distintos portales para mostrarlas todas en un solo lugar. Así no tienes que ir buscándolas una por una. El scraper entra en esas webs, busca los nuevos anuncios y los guarda en una base de datos para que los usuarios los puedan consultar fácilmente.
4. Control de reputación en internet
Las empresas quieren saber qué se dice de ellas en redes sociales, foros o medios digitales. Para ello, pueden usar scraping para recopilar esas menciones y analizarlas. Así pueden detectar críticas, comentarios positivos o problemas que deben solucionar cuanto antes.
5. Seguimiento de noticias y tendencias
Los medios de comunicación y las agencias de marketing usan crawlers para seguir noticias que aparecen en diferentes sitios web. Esto les permite detectar temas que están generando interés y saber qué contenido se está compartiendo más.
6. Investigación académica o científica
Universidades o centros de estudio pueden usar scraping para recoger información de publicaciones, bases de datos o páginas web con contenido especializado. Así pueden analizar muchos datos sin tener que copiarlos a mano uno a uno.
7. Alertas de cambios en páginas web
Algunas personas o empresas quieren saber si una web concreta ha cambiado, por ejemplo, si ha bajado el precio de un producto o si han publicado un nuevo artículo. Existen herramientas que hacen crawling en esa web y envían una alerta automática si detectan cambios.
| Aplicación | ¿Qué hace el crawler o el scraper? |
|---|---|
| Motores de búsqueda | Recorren páginas web para descubrir, indexar y actualizar contenidos. |
| Comparadores de precios | Extraen precios y productos de diferentes tiendas online. |
| Buscadores de empleo | Recolectan ofertas de trabajo de varios portales en un solo sitio. |
| Seguimiento de reputación | Detectan menciones en redes sociales, foros o noticias sobre una marca. |
| Monitoreo de noticias | Detectan tendencias y temas populares en medios digitales. |
| Investigación académica | Recopilan datos de publicaciones científicas o bases de datos abiertas. |
| Alertas de cambios web | Detectan actualizaciones en páginas concretas y avisan al usuario. |
¿Es legal hacer web crawling y web scraping?
La respuesta corta es: depende. El web crawling y el web scraping no son ilegales por sí mismos, pero su legalidad depende de cómo y para qué se usen. Vamos a verlo con más detalle.
En general, rastrear páginas públicas de internet no suele ser un problema, sobre todo si se hace con cuidado y sin dañar el sitio web. Los buscadores como Google lo hacen constantemente y nadie los prohíbe. Pero hay algunas condiciones que hay que respetar.
Por ejemplo, muchas webs indican en su archivo robots.txt qué partes del sitio se pueden rastrear y cuáles no. Este archivo funciona como un cartel de “prohibido pasar” para los crawlers. Aunque no es una ley, ignorar estas indicaciones puede considerarse una mala práctica y en algunos casos, puede tener consecuencias legales.
En el caso del scraping, hay que tener todavía más cuidado. Si vas a extraer datos protegidos por derechos de autor, como textos completos, imágenes o bases de datos privadas, puedes meterte en problemas legales. Lo mismo ocurre si se copian datos personales sin permiso o si se rompe alguna condición de uso del sitio web.
En Europa, por ejemplo, el Reglamento General de Protección de Datos (RGPD) protege la información personal. Si haces scraping de datos personales sin base legal o sin informar a los usuarios, podrías estar infringiendo esa ley.
También hay que tener en cuenta el impacto técnico. Si haces demasiadas peticiones en poco tiempo, puedes saturar el servidor de la web objetivo. Eso puede provocar fallos o caídas, y se considera una conducta abusiva.
En resumen:
- Sí se puede hacer crawling y scraping de forma legal, siempre que se respeten las reglas del sitio web.
- No copies contenido completo sin permiso, ni recojas datos personales sin motivo justificado.
- Consulta el robots.txt y evita afectar negativamente al rendimiento de las páginas que visitas.
- Actúa con responsabilidad, como si estuvieras visitando un sitio web ajeno en persona.
Conclusión
El web crawling y el web scraping son dos técnicas clave para entender cómo funciona internet por dentro. Gracias a ellas, los buscadores pueden encontrar información nueva, las empresas pueden analizar a la competencia y los usuarios pueden acceder a datos sin tener que buscarlos manualmente.
Aunque pueden parecer procesos muy técnicos, en realidad están presentes en muchas herramientas y páginas que usamos cada día. Saber cómo funcionan nos ayuda no solo a entender mejor la web, sino también a aprovechar sus ventajas de forma responsable y legal.
Además, si tienes una página propia, es importante que esté bien preparada para recibir a los crawlers de los buscadores. Una estructura clara, contenido de calidad y un buen rendimiento son factores clave para posicionarte mejor. Por eso, contar con un buen servicio de hosting web también marca la diferencia a la hora de optimizar tu sitio.
Ahora que ya conoces cómo se explora y se extrae información de la web, tienes una base sólida para seguir aprendiendo sobre SEO, automatización y análisis de datos. ¡El siguiente paso está en tus manos!